| SOTA!DFR | 您所在的位置:网站首页 › 多目标跟踪MOT最新综述一文快速入门 › SOTA!DFR |
SOTA!DFR
|
点击下方卡片,关注“自动驾驶之心”公众号 ADAS巨卷干货,即可获取 点击进入→自动驾驶之心【目标跟踪】技术交流群 后台回复【目标跟踪综述】获取单目标、多目标、基于学习方法的领域综述! 1摘要持久多目标跟踪(MOT)允许自动驾驶车辆在高度动态的环境中安全导航。MOT中的一个众所周知的挑战是当目标在后续帧中变得不可观察时的目标遮挡。当前的MOT方法将目标信息(如目标的轨迹)存储在记忆中,以在遮挡后恢复目标。然而,它们保留了短期记忆,以节省计算时间并避免减慢MOT方法。因此,在某些遮挡场景(特别是长遮挡场景)中,它们会丢失对目标的跟踪。本文提出了DFR-FastMOT,这是一种轻型MOT方法,它使用来自相机和激光雷达传感器的数据,并依赖于目标关联和融合的代数公式。该公式提高了计算时间,并允许长期记忆,以应对更多的遮挡场景。与最近的学习和非学习基准相比,MOTA的跟踪性能表现突出,分别提升约为3%和4%。此外论文还进行了大量实验,通过使用具有不同失真水平的检测器来模拟遮挡现象。与现有技术方法相比,所提出的解决方案能够在检测中的各种失真水平下实现优异的性能。本文的框架在1.48秒内处理约7763帧,比最近的基准测试快了7倍。 总结来说,论文的主要贡献如下: 提出了一种轻型MOT框架,与当前的学习和非学习MOT方法相比,该框架具有显著的跟踪性能,计算时间更短,比最近的非学习方法快约七倍; 论文通过使用各种检测失真水平来模拟遮挡现象,以评估论文的解决方案在目标遮挡下的性能。该框架在整个实验中显示出优于其他基准的性能; 论文展示了该框架在不同类型的遮挡下跟踪目标的能力,如现场外目标、具有单个检测信息2D/3D的目标和多目标遮挡。 2文献综述许多研究工作提出了在目标跟踪[7]-[11]中的出色性能,这些工作采用了先检测后跟踪范式。Bewley等人[12]介绍了在线MOT的SORT,其中他们使用卡尔曼滤波器(KF)[6]使用历史观测来估计物体的轨迹。他们使用匈牙利算法[13]来关联后续帧中的目标。另一方面,Bochinski等人[14]利用高速率帧和复杂的检测器,使用IoU关联目标。因此,作为MOT方法,他们实现了具有竞争力的速度。 尽管这些跟踪器实现了出色的性能,但目标遮挡仍然具有挑战性,因为它们需要处理被跟踪目标的记忆。此外他们假设观察者总是静态的,这在观察者通常处于运动状态的AV应用中不适用。此外,当最好融合多传感器数据以克服单传感器故障时,他们将单传感器用于MOT。 其他研究工作提出了针对AVs的MOT解决方案。论文将讨论使用单传感器[1]–[3]、[15]、[16]和多传感器[4]、[5]、[17]–[19]的研究工作,并强调每种传感器的优缺点。 Chaabane等人[1]提出了一种联合深度学习模型,该模型通过集成LSTM模型[20]来捕获运动约束,根据捕获的相机帧中的目标外观来组成检测和跟踪任务。然而,该方法需要解决目标遮挡问题。因此,Tokmakov等人[2]引入了一种由时空和循环记忆模块支持的目标持久性跟踪器,该模块使用整个历史来识别观察到的目标的位置和身份。尽管它们在跟踪被遮挡目标方面具有优异的性能,但它们对长期运行中可能会损害关联效率的目标保持永久历史记录。此外,利用一个信息源会降低解决方案的鲁棒性。 另一方面,研究工作[4]、[5]、[17]考虑了使用多传感器融合的目标跟踪。这些方法使用来自2D相机和3D激光雷达点云的复杂检测器获得信息。Kim等人[5]使用预训练的深度学习模型[21]-[23]进行目标检测。接下来,他们通过使用IoU将检测结果与先前观测结果相关联,利用KF来估计物体轨迹。这项工作的局限性在于,他们使用了一个朴素的KF模型,该模型假设物体始终具有恒定的速度,这不适用于汽车等物体。Wang[18]和Kim[19]应用非线性滤波器来估计跟踪目标的复杂运动。Kim[19]使用LiDAR和雷达传感器的物体距离,利用扩展的KF跟踪物体,并通过在不同场景下操作Prescan模拟器[24]显示结果。相比之下,Wang[18]提出了用于状态估计的无迹KF的修改版本,提高了跟踪精度。同时,Weng等人[25]使用基线算法,匈牙利算法[13],并展示了基线算法实现与所提出的深度学习解决方案相当的跟踪精度的能力。 前面的工作使用了目标的短期记忆,防止捕捉某些遮挡场景,这最终会影响整体跟踪性能。本文通过引入关联和融合步骤的代数公式来解决这个问题,该公式提高了MOT计算时间并允许长期记忆的集成。 3方法论该框架在时间接受来自摄像机和LiDAR的2D和3D检测,并在匹配阶段统一检测到的目标,以防止相同目标的重复信息。接下来将检测与存储器中先前观察到的目标相关联,以获得不匹配目标和匹配目标的集合。记忆模块更新匹配目标的历史记录,并将不匹配目标添加为新目标。此外,记忆模块丢弃在超过帧数的帧内未出现的老化目标。论文最终使用具有恒定加速度的KF来更新存储在存储器中的目标的轨迹,并基于轨迹的变化获得后续帧的状态估计。图2显示了该框架的概述。 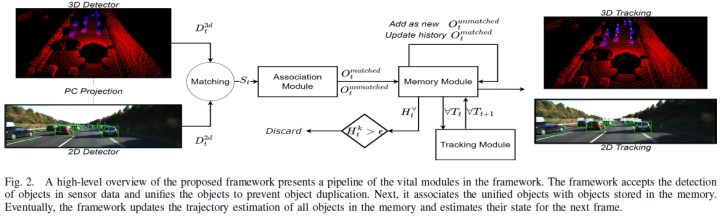 A.检测模块
A.检测模块
该框架需要来自相机和激光雷达传感器的输入数据,然而其可以仅依靠2D或3D检测器来实现跟踪。如图2所示,该框架可以使用2D或3D单检测器,并使用标定参数和点云投影获得其他检测信息,该点云投影允许从相机到LiDAR系统坐标的转换,反之亦然。采用单个检测的本质是使该框架适用于实时应用,当采用两个检测器时,某些AV的功耗和硬件要求会很高,尤其是移动机器人。 在多检测器的情况下,论文涉及一个额外的步骤,即匹配2D和3D检测结果,以防止对同一目标的检测重复。为了实现这一点,论文使用了相同的单检测器步骤,通过从获得目标的2D检测。然后,当从转换的2D边界框与中的一个目标匹配时,此时考虑目标的检测重复。在匹配的情况下,论文将和中的匹配数据分配给目标,否则检测将被分类为两个不同的目标。因此,结果是包含具有2D、3D或检测组合的目标的一组目标集合。 B.关联模块该框架以代数公式实现关联和融合步骤,使其比最近发布的基准测试快七倍[4][5]。论文首先为每个传感器引入一个关联矩阵,即方程1,相机的关联矩阵和LiDAR传感器的关联矩阵。矩阵具有与等式1相同的公式,其中行数m是传感器当前检测到的目标的数量,列数n是存储在存储器中的目标的数目。表示最近检测到的目标和存储在存储器中的目标之间的关联值。 
在融合部分,使用等式2合并关联矩阵以获得融合的关联矩阵。和表示矩阵的重要性。例如,如果LiDAR检测提供了鲁棒的关联结果,而不是相机检测,将通过增加和减少来信任而不是。 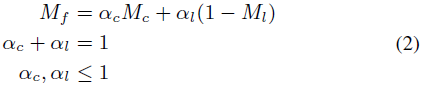
1) 相机关联矩阵():为了关联2D帧中的两个目标,论文在一定阈值下使用IoU。两个目标之间的关联值可以表示如下: 
2) LiDAR关联矩阵():为了处理更多的目标遮挡,论文没有将IoU用于3D关联矩阵,而是改用3D质心距离[26]。当发生长时间遮挡时,估计的边界框和当前检测到的边界框之间不太可能相交。因此计算3D边界框的质心之间的欧几里德距离,这为重新识别遮挡目标提供了更大的灵活性。论文使用与矩阵类似的策略,将作为欧几里德距离阈值。的分配如下: 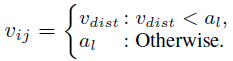
为了使和相等地融合,需要确保两个矩阵的值都在0和1之间,而的情况并非如此。因此通过除以最大值来归一化,以获得归一化矩阵。最终需要反转这种行为以匹配矩阵。因此论文进行(),以获得相反的行为。因此,当收敛为一个目标时,表示匹配的目标。 使用等式2,本文获得了融合矩阵,该融合矩阵组合了来自传感器的关联矩阵。最终进行了类似于匈牙利算法[13]的算法,以在关联阈值下从获得目标的最终关联。选择中存在的最大值。然后关联相应的目标并重复相同的算法,直到最大值低于阈值。在这种情况下,算法终止。在最坏的情况下,搜索中的所有元素需要,这是匹配中所有目标的复杂度。 C.跟踪模块跟踪模块对存储在存储器中的所有目标执行KF。该过程涉及两个中心状态:更新状态和预测状态。模块更新在时间计算的物体轨迹估计在2D相机帧和3D LiDAR点云中使用传感器对目标的当前观察。模块在更新状态下更新目标的位置、速度和加速度。在预测状态下,模块计算两个空间中的物体位置和的以下估计,给出每个物体可用的最近更新的参数、速度和加速度。在遮挡中,该模块仅启动预测状态,这意味着物体位置和速度的估计将发生变化,同时加速度将是相同的,因为论文使用恒定加速度模型。图3显示了目标遮挡的三种场景,以及论文的方法如何在给定2D、3D或两种轨迹信息的情况下检索被遮挡的目标。 为了减少计算时间,论文将KF系统和目标数据表示为矩阵,并将KF估计应用于绘制2D和3D边界框所需的最少点数,这是两个边界点。对于2D边界框,仅使用左上角和右下角点来执行KF操作,在3D边界框的情况下,使用左上和右下对角点。采用以下步骤对对象进行KF估计: 第一次观测:当第一次观测目标时,将检测到的边界框位置指定为对象的初始状态,然后是KF预测状态,以获得状态估计; 单传感器观测:为了简化,假设LiDAR传感器只观测物体。在这种情况下,对3D边界框数据执行KF的更新和预测状态,并对最后估计的2D边界框(如果可用)执行预测步骤; 多传感器观测:如果LiDAR和相机观测到物体,将对2D和3D边界框信息执行KF的更新和预测状态; 未观测到:在未观测到目标的情况下,仍然对2D和3D边界框信息执行KF的预测状态,以跟踪目标的未来外观。 D.记忆模块记忆模块对于物体遮挡至关重要。本文的框架使长期记忆能够捕捉大范围遮挡场景,如图3所示。如图2所示,丢弃了在后续帧中不出现的老化目标。为此使用等式3来选择在时间处,对于多个帧,相机没有观察到目标的最小数量的后续帧,对于多帧,选择LiDAR。 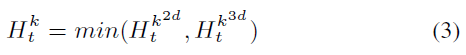
如前文所述,框架一致地更新记忆中所有剩余目标的KF估计,并存储新的状态估计以稍后集成到关联模块中。 4结果和讨论 A.数据集和实验设置论文在KITTI[32][33]数据集上进行实验,该数据集涉及21个具有约8000个连续帧的流,因为它包含在德国卡尔斯鲁厄驾驶时各种城市场景的长流持续时间。本文使用数据集中提供的激光雷达和相机信息以及标定参数。使用KITTI评估工具[34]进行评估。为了提供与基准模型的透明比较,选择了最近的两个基准,即EagleMOT[5]和DeepFusion MOT[4],它们提供了可修改的源代码来集成和运行各种检测器。论文在以下硬件方案上进行了实验:处理器:第11代Intel Core i7-11370H 3.30GHz,GPU:NVIDIA Geforce RTX3070笔记本电脑GPU。然而,本文的框架只使用CPU来进行跟踪。 B.检测失真下的评估高检测失真意味着检测器经常由于检测器差而失去对目标的检测,因此当我们在后续帧中失去对目标检测时,失真类似于目标遮挡。相反合适的检测器具有较小的检测失真。在这个实验中,论文通过传导具有不同检测失真的检测器来模拟遮挡现象:低、中和高。作者运行了最近两个基准测试的源代码,EagleMot[5]和DeepFusion MOT[4],并使用KITTI评估工具包[34][33]。论文涉及来自训练和验证数据集的20个流。表I显示了实验的概述结果,可以总结如下: 
检测器差(高失真):表I中的第一行显示了一个使用差检测性能的实验。对2D检测使用YOLOv3[27],并使用标定参数投影点云以获得3D检测。本文的跟踪器在HOTA和MOTA中分别达到39.2%和44.5%,比EagleMOT[5]高3%,比DeepFusion MOT[4]高12%。且具有42.8%的高关联精度,与其他跟踪器相比,id切换更少。由于较差的检测意味着对目标的检测不一致,因此结果反映了在不一致或断开检测情况下跟踪器的稳定性。本文的跟踪器在检测不一致方面优于两个基准。 中等检测器(中等失真):表I的第二行显示了中等性能检测器下的跟踪性能。通过用更复杂的检测器RCC[28]替换YOLOv3[27],进行了与先前实验类似的设置,但几乎没有修改。仍然通过点云投影获得3D检测。结果表明,DeepFusion MOT[4]无法在3D检测不佳的情况下表现良好。相比之下,EagleMOT[5]的性能有所改善,HOTA达到70.8%,MOTA达到82.2%。然而本文的跟踪器在HOTA和MOTA指标上仍比EagleMOT[5]高出近11%。且也具有较少的id切换,即使3D检测较差,这对于EagleMOT[5]和DeepFusion[4]都是相反的。最后论文的模型可以实现最高的MOTA值,即91%,只需传导一个检测器,比其他基准高5%。 良好的检测器(低失真):表I中的最后四行显示了利用复杂的2D和3D检测器的跟踪结果。在本实验中,论文在RCC[28]和TrackRCNN[31]2D检测器以及PointGNN[30]和PorintRCN[29]3D检测器之间切换。因此有四行表示所有可能的组合。本文的跟踪器在HOTA和MOTA的总体性能通常分别为82.8%和90.7%。该跟踪器在不同的2D检测器组合下具有优异的性能。然而,EagleMOT[5]与TrackRCNN[31](用于2D检测)和PointGNN[30](用于3D检测)相比具有优异的性能。EagleMOT[5]与PointGNN[30]的性能优于PointRCNN[29],这解释了在放置PointGNN[3]的第六行和第四行中,EagleMOT[5]的性能几乎相似。 总之,无论所分配的检测器的性能如何,本文的跟踪器都保持着优异的性能。且在实验中具有稳定的id切换,这不适用于IDSW爆炸时具有较差和中等检测器性能的其他基准。然而,本文的方法具有比2D和3D良好检测器的基准更高的IDSW,这可能是由于在本文的框架中保持长期记忆以处理长时间遮挡而获得的噪声所致。 论文参考KITTI评估数据集上的声明结果,使用其他基准进行了另一次评估,并通过在本文的机器上运行EagleMOT[5]和DeepFusion MOT[4]框架获得了跟踪结果。比较包括最近的学习和非学习跟踪方法。尽管PC-TCNN[3]跟踪器作为一种基于学习的方法实现了比其他基准更高的性能,但论文的跟踪器优于基准模型,包括基于学习的方式,在MOTA中有3%的余量。如表II所示,跟踪器仅使用带有点云投影的RCC 2D检测器,就实现了93.06%的MOTA精度。注意到,跟踪器在评估流中具有一致的性能,允许高AMOTA,90.79%,显著高于最近的基准。使用2D RCC[28]和3D PointRCNN[29]检测器实现了最高的HOTA,84.28%。  C.使用学习和非学习基准进行评估
C.使用学习和非学习基准进行评估
论文参考KITTI评估数据集上的声明结果,使用其他基准进行了另一次评估,并通过在本文的机器上运行EagleMOT[5]和DeepFusion MOT[4]框架获得了跟踪结果。比较包括最近的学习和非学习跟踪方法。尽管PC-TCNN[3]跟踪器作为一种基于学习的方法实现了比其他基准更高的性能,但论文的跟踪器优于基准模型,包括基于学习的方式,在MOTA中有3%的余量。如表II所示,跟踪器仅使用带有点云投影的RCC 2D检测器,就实现了93.06%的MOTA精度。注意到,跟踪器在评估流中具有一致的性能,允许高AMOTA,90.79%,显著高于最近的基准。使用2D RCC[28]和3D PointRCNN[29]检测器实现了最高的HOTA,84.28%。  D.耗时对比
D.耗时对比
为了评估耗时,论文为所有跟踪器安装了2D RCC[28]和3D PointRCNN[29]检测器,在同一台机器上单独运行每个跟踪器,并记录源代码打印的时间。如表III所示,本文的跟踪器在1.48秒内处理数据集,这比其他基准测试快大约七倍。  5结论
5结论
本文提出了一种轻量级MOT方法,该方法依赖于代数模型来融合和关联相机和激光雷达传感器检测到的物体。实验表明,关联和融合步骤的代数公式显著减少了MOT方法的计算时间。这一优势允许MOT方法中的长期记忆扩展,最终捕获复杂的目标遮挡场景并提高整体跟踪性能。论文使用不同的检测失真水平来模拟目标遮挡现象,并表明本文的方法在不一致检测下优于最近的两个基准。此外还针对基于学习的和非学习的方法评估了论文的解决方案,并表明DFR-FastMOT在很大程度上优于最近基于学习的研究工作,在MOTA中为3%,而使用单个检测器的其他方法为4%,使其适用于移动机器人。 6参考[1] DFR-FastMOT: Detection Failure Resistant Tracker for Fast Multi-Object Tracking Based on Sensor Fusion
国内首个自动驾驶学习社区 近1000人的交流社区,和20+自动驾驶技术栈学习路线,想要了解更多自动驾驶感知(分类、检测、分割、关键点、车道线、3D目标检测、多传感器融合、目标跟踪、光流估计、轨迹预测)、自动驾驶定位建图(SLAM、高精地图)、自动驾驶规划控制、领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频,期待交流!
【自动驾驶之心】全栈技术交流群 自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D目标检测、BEV感知、多传感器融合、SLAM、光流估计、深度估计、轨迹预测、高精地图、NeRF、规划控制、模型部署落地、自动驾驶仿真测试、产品经理、硬件配置、AI求职交流等方向;
添加汽车人助理微信邀请入群 备注:学校/公司+方向+昵称 |




【本文地址】